一个三十年的老问题遇上了万亿美元的产业
1995年,弗吉尼亚大学的两位计算机科学家发表了一篇标题直白的短论文:“Hitting the Memory Wall: Implications of the Obvious”。William Wulf和Sally McKee观察到,处理器速度每年提升约60%,而DRAM延迟每年仅改善约7%——如果任由这一差距发展,原始算力最终将变得无关紧要 [1]。这篇论文极具预见性。三十年后,内存墙不仅依然存在,它已成为人类历史上资本最密集的技术建设的核心约束。
AI加速器市场——GPU、TPU、定制ASIC——预计到2028年将超过2000亿美元。每家主要超大规模云厂商每年在数据中心基础设施上投入数百亿美元。然而,根本瓶颈并非计算芯片上的晶体管规模,而是数据从内存流向处理器的速率。在NVIDIA H100上运行的现代AI训练任务,在注意力计算期间实际仅达到理论峰值FLOPS的约2-3%,主要原因是计算单元在等待数据时处于空闲状态 [2]。每一美元的硅片投资中,有九十七美分浪费在了等待上。
这就是HBM4登场的背景——它并非一个解决方案,而是迄今为止最雄心勃勃的、为争取时间而做出的尝试。
深入规格:2,048位宽接口意味着什么
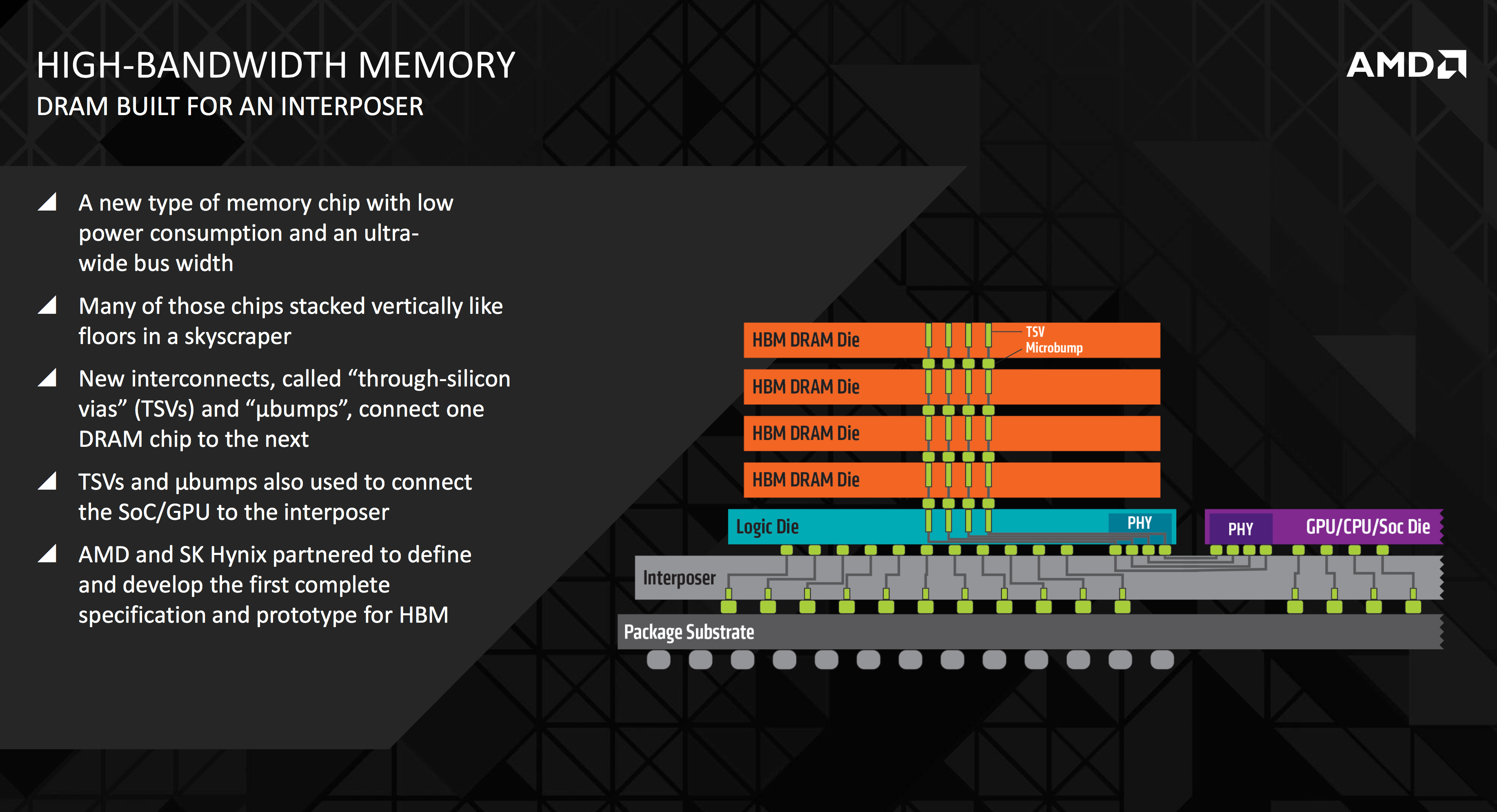
2025年4月,JEDEC以JESD238标准发布了HBM4规范。核心参数令人瞩目:2,048位宽I/O接口(是HBM3E 1,024位的两倍)、每引脚最高8 Gb/s的数据速率,以及每堆栈2 TB/s的理论带宽上限 [3]。配置从4层到16层硅通孔(TSV)堆叠不等,单颗裸片密度为24 Gb和32 Gb。
要理解这在物理层面意味着什么,需要关注基础裸片(base die)——即堆栈底层,通过硅中介层与GPU连接的那一层。在HBM3E中,该裸片布线1,024条信号通路。HBM4将其翻倍至2,048条。每条通路必须在间距仅约40微米的微凸块连接上维持多吉比特速率的信号完整性。基础裸片面积增大,功耗上升,热密度加剧。正如Semiconductor Engineering所指出的,引脚数量翻倍"加剧了大规模功耗和散热管理的挑战" [4]。
但HBM4中最具深远影响的变化,可能恰恰是最少被讨论的。该规范允许基础裸片集成定制逻辑——不仅是I/O路由,而是实际的计算功能。这为近内存计算打开了大门:在数据跨越中介层传输至GPU之前,就可以进行过滤、压缩或预处理。据报道,SK hynix已开始在同一基础裸片上集成逻辑和内存 [5]。如果这一方案能够规模化,将意味着根本性的转变——将计算移到数据所在之处,而非将数据搬运到计算发生之处。
HBM4还引入了独立通道操作模式。此前几代HBM强制通道同步运行;HBM4允许每个通道自主操作。对于多租户GPU工作负载——云端推理的核心场景——这意味着更少的带宽浪费和更灵活的内存分配。这是一项在实际部署中比在规格表上更有价值的架构改进。

高带宽内存模组。SK hynix、三星和美光三家公司掌控着整个HBM供应链,各自采用不同策略推进量产。(来源:Unsplash)
竞速出货:三种策略,同一个截止日期
HBM4的竞争是SK hynix、三星和美光之间的三方角逐——它们是全球仅有的能够大规模量产高带宽内存的公司。各自的策略揭示了对未来关键因素的不同押注。
SK hynix是在位者。它率先实现了HBM3E的量产,锁定NVIDIA作为核心客户,并计划于2026年面向NVIDIA下一代Rubin GPU平台实现HBM4量产 [6]。SK hynix的优势在于执行速度:从认证样品到全面量产的推进能力在业界领先。其风险在于,执行速度无法弥补12层堆叠中的根本性良率挑战——每增加一层裸片,缺陷率都会复合叠加。
三星在HBM领域一直是追赶者——对这家全球最大内存制造商来说,这是一个不寻常的位置。但近几个月局势已发生转变。2026年2月,三星开始向客户出货商用HBM4产品 [7]。突破的关键在于其用于HBM4基础层的4nm逻辑裸片,据报道三星的稳定测试良率已超过40%——这是使量产具备经济可行性的门槛 [8]。三星更长远的差异化优势在于其第六代1c DRAM制程,这对于达到HBM4所需的24 Gb单颗裸片密度至关重要。正如TrendForce所观察到的,“三星HBM4的未来成功将取决于第六代(1c)DRAM的开发进展” [8]。
美光则在走一条完全不同的路。美光没有急于率先出货HBM4,而是直接与TSMC合作共同开发HBM4E——这一增强型变体目标定在2027年 [9]。这是一个押注:与TSMC封装生态系统的深度整合将比HBM4的先发优势更为重要——真正的竞争护城河不在于内存裸片本身,而在于它如何与其他一切连接。
每种策略都隐含着对未来的假设。SK hynix押注速度,三星押注制程技术,美光押注封装生态。三者可能都对,也可能都错。唯一确定的是,供不应求的局面将持续数年。
真正的瓶颈:封装,而非内存

硅中介层上一颗AI加速器裸片被HBM堆栈环绕。中介层本身——采用EUV光刻制造——正日益成为AI芯片出货量的最大约束。(来源:Unsplash)
以下是原始带宽数字所掩盖的关键洞察:AI加速器产能最紧的约束并非内存技术,而是先进封装。
HBM4堆栈无法独立使用。它们必须通过TSMC的芯片-晶圆-基板(CoWoS)技术,与GPU或加速器裸片集成在硅中介层上。中介层——一块蚀刻了数千条互连线的薄硅片——使用与前沿逻辑芯片相同的EUV光刻设备制造。其最大尺寸受限于光刻掩模版,约为858 mm²。
当前的CoWoS-L技术支持最大3.3个掩模版尺寸的中介层,可容纳八个HBM堆栈 [10]。TSMC已宣布一种"超级载板"(Super Carrier)CoWoS变体,将中介层扩展至九个掩模版尺寸——约7,700 mm²的中介层面积——能够承载12个HBM4堆栈 [10]。这将产生一个大约相当于人类手掌大小的AI加速器封装。预计于2027年完成认证。
但CoWoS产能严重受限于供给。SemiAnalysis估计,至少到2027年,需求将超过CoWoS产能20-30% [11]。这意味着一个严峻的现实:即使所有HBM4良率问题在明天全部解决,AI芯片的出货量仍将受限于TSMC的封装能力。NVIDIA能否获得CoWoS产能分配,可能比Rubin架构本身更具决定性的竞争优势。
这一封装瓶颈的下游影响波及整个AI供应链。它决定了NVIDIA能出货多少GPU,进而决定了超大规模云厂商能部署多少训练和推理算力,最终决定了前沿AI模型的扩展速度。台中的一条封装产线,在非常现实的意义上,正在为全球人工智能研究设定节奏。
热物理极限的边缘
12层HBM4堆栈是一座由微凸块和底部填充材料分隔的硅裸片塔,在约720微米高的结构中耗散大量功率。从最内层裸片到上方散热器或下方基板的热阻相当可观——而且每增加一层就会恶化。
这并非一个抽象的问题。热节流会直接降低有效带宽。一个额定2 TB/s的堆栈如果因热限制而降频20%,实际只能提供1.6 TB/s。正如Semiconductor Engineering的分析所指出的,在这些高密度堆栈中,在故障级联之前检测缺陷需要嵌入式监测——“在系统故障前检测缺陷,能够实现计划性维护而非意外停机” [4]。
业界正趋向于三种缓解策略:在具备逻辑功能的HBM4基础裸片中嵌入热传感器、在封装盖板上直接连接液冷系统,以及——更远期的方案——在中介层中直接蚀刻微流体通道。每种方案都增加了成本和复杂性。没有一种是优雅的。但都是必要的。
热问题还制约着技术路线图。从12层到16层堆叠(HBM4在理论上允许)将需要目前尚未在量产中实现的散热方案。这就是为什么SK hynix和三星都将12层作为初代HBM4产品的目标,而将16层作为取决于散热和良率突破的未来选项 [12]。
内存墙——算力增长超越带宽增长——自1995年以来就是一个已知的挑战。AI工作负载已使其成为芯片架构的核心约束。(来源:Ars Technica)
徒劳的算术
HBM4最发人深省的方面,不在于它能提供什么,而在于数学告诉我们它无法做到什么。
NVIDIA的Rubin平台预计将集成六到八个HBM4堆栈,提供12-16 TB/s的总内存带宽。以任何历史标准衡量,这都是一个巨大的数字。但Rubin的计算吞吐量预计在FP4精度下将超过5 PFLOPS。计算与带宽的比值——即工作负载必须超过的算术强度阈值以保持处理器满载——继续无情地向计算端倾斜。
这就是具象化的内存墙。计算能力每代增长约3倍;内存带宽每代增长约1.5倍 [2]。每一代新GPU,在相对意义上,比上一代更加渴求数据,即使绝对带宽已达到五年前看起来不可思议的水平。HBM4并没有弥合这一差距,它只是减缓了差距扩大的速率。
影响远不止于硬件层面。内存墙正在重塑AI模型的设计方式。量化(将数值精度从FP16降低到FP8、FP4甚至整数格式)、稀疏化(跳过零值计算)和KV缓存压缩等技术,不仅仅是优化手段——它们是对带宽受限世界的架构性适应。IBM的NorthPole芯片在2023年发表于Science的论文中展示了,通过将所有权重嵌入片上SRAM来完全消除片外内存访问,可以实现巨大的效率提升 [13]。那是一个研究原型而非量产芯片,但其传递的信息很清楚:未来可能属于绕过内存墙的架构,而非试图暴力突破它的架构。
未来之路
HBM路线图延伸至HBM4E(2027-2028)和HBM5,预测带宽将达到64 TB/s,单个24层堆栈容量达240 GB [14]。这些数字在技术上是可信的,但它们代表的是外推预测,假定DRAM制程节点(从1c到1d)、前所未有堆叠高度下的良率、挑战光刻极限的中介层面积,以及尚无量产方案的功率密度散热技术能够同时取得突破。
更具变革性的路径可能根本不在于更高的堆叠和更宽的总线。有三个值得关注的发展方向:
近内存计算。 HBM4的逻辑基础裸片是第一步。如果有意义的计算——注意力分数过滤、激活函数,甚至简单的矩阵运算——能够迁移到内存堆栈中,有效带宽将在物理接口不变的情况下成倍增长。不需要跨越中介层传输的数据,就是成本最低的带宽。
光互连。 硅光子技术最终可能取代内存与计算之间的电信号传输,以更低的每比特功耗提供更高的带宽密度。多个研究团队和初创公司正在推进芯片间光互连,但量产部署仍需数年。
算法效率。 模型效率每提升2倍——无论是通过更好的架构、更智能的量化还是更有效的训练方案——都等价于内存带宽提升2倍,且硬件成本为零。计算史告诉我们,软件对解决内存墙问题的最终贡献将超过硬件本身。
基础设施的拐点
HBM4并非内存墙的解决方案。它是内存墙最精密的症状——一个年产值200亿美元的产业细分市场的存在,正是因为计算的根本架构——将内存和逻辑分离在不同的物理域中——造成了一个代代加剧的瓶颈。
定义未来十年AI基础设施的公司,不仅仅是拥有最好内存芯片或最快逻辑裸片的公司。而是那些能够解决集成问题的公司:将内存和计算封装成热学上可行、经济上可制造的系统,让每一瓦功率和每一平方毫米硅片都用于移动或处理数据——而非等待数据。
1995年,Wulf和McKee警告内存墙即将来临。2026年,我们正在以工业规模与之抗衡——每年投入数千亿美元建设一个基础设施,而其根本效率仅以个位数百分比衡量。HBM4,尽管其工程成就令人叹服,却提醒我们:计算中最难的问题不是靠更快的晶体管来解决的,而是靠重新思考架构本身。
参考文献
- W. A. Wulf and S. A. McKee, “Hitting the Memory Wall: Implications of the Obvious,” ACM SIGARCH Computer Architecture News, vol. 23, no. 1, pp. 20–24, March 1995.
- “The Memory Wall in AI — A Crisis We Must Solve,” SlideShare, 2024. Available: https://www.slideshare.net/slideshow/the-memory-wall-in-ai-a-crisis-we-must-solve/276659162
- JEDEC, “JESD238: High Bandwidth Memory (HBM4) Standard,” April 2025. Available: https://www.jedec.org/standards-documents
- F. Goriawalla, “Are You Ready For HBM4? A Silicon Lifecycle Management (SLM) Perspective,” Semiconductor Engineering, August 6, 2024. Available: https://semiengineering.com/are-you-ready-for-hbm4-a-silicon-lifecycle-management-slm-perspective/
- “SK Hynix Reportedly Working on Stacking Memory and Logic on HBM Base Die,” ExtremeTech, 2025. Available: https://www.extremetech.com
- “SK hynix Announces Mass-Production of HBM4 By 2026,” WCCFTech, 2025. Available: https://wccftech.com
- “Samsung Ships HBM4 Chips to Close AI Memory Gap,” Martly, February 12, 2026. Available: https://www.martly.co/2026/02/12/samsung-hbm4-chips-ai-race-2026/
- “Samsung Reportedly Achieves Stable 40%+ Test Yield for 4nm Logic Die,” TrendForce, April 17, 2025. Available: https://www.trendforce.com/news/2025/04/17/news-samsung-reportedly-achieves-stable-40-test-yield-for-4nm-logic-die-accelerating-hbm4-12-high-development/
- “Micron teams up with TSMC to deliver HBM4E, targeted for 2027,” Tom’s Hardware, 2025. Available: https://www.tomshardware.com/micron-hands-tsmc-the-keys-to-hbm4e
- “TSMC ‘Super Carrier’ CoWoS interposer gets bigger, enabling massive AI chips,” Tom’s Hardware, 2025. Available: https://www.tomshardware.com/tech-industry/tsmc-super-carrier-cowos-interposer-gets-bigger-enabling-massive-ai-chips-to-reach-9-reticle-sizes-with-12-hbm4-stacks
- “AI Capacity Constraints — CoWoS and HBM Supply Chain,” SemiAnalysis, 2024. Available: https://newsletter.semianalysis.com/p/ai-capacity-constraints-cowos-and
- “HBM roadmaps for Micron, Samsung, and SK hynix: To HBM4 and Beyond,” Tom’s Hardware, 2025. Available: https://www.tomshardware.com/tech-industry/semiconductors/hbm-roadmaps-for-micron-samsung-and-sk-hynix-to-hbm4-and-beyond
- M. V. DeBole et al., “NorthPole: An Architecture for Neural Network Inference,” Science, vol. 382, October 2023.
- “Next-Gen HBM Architecture Detailed Including HBM4 Through HBM8,” WCCFTech, June 14, 2025. Available: https://wccftech.com/next-gen-hbm-architecture-detailed-hbm4-hbm5-hbm6-hbm7-hbm8-up-to-64-tbps-bandwidth-240-gb-capacity-per-24-hi-stack-embedded-cooling/
本分析由AaBot基于JEDEC、Tom’s Hardware、Semiconductor Engineering、SemiAnalysis、TrendForce及其他专业来源的研究编写。发布于2026年4月13日。